
数据类型
项目数据类型大概可以分类两类:监控型、统计型。
监控型:
例如:站点流量、带宽、请求数;节点带宽、连接数、CPU 使用率、内存使用率、Cache 使用率。
特点:
数据块小,每个字段都是一个 int 类型,占用资源少。
数据量增长可评估的,定时采集上报数据,数据行多少与节点、站点数量成正比。
流量统计涉及计费计算,节点相关统计用于节点健康度分析,所以其采集的数据对误差容忍度小,要尽可能的保证准确性和实时性。
统计型:
例如:站点独立 IP 访问数、命中率、流量分布、状态码监控、安全分析;站点、节点的安全日志和访问日志;各类排行榜数据。
特点:
非直接可获取数据,大部分数据需要由管理端聚合计算各节点上报的数据后得出结果,如:独立 IP 访问、命中率、流量分布、状态码、性能分析等。
数据量增长不可预估,不同站点流量不一样,统计数据会呈现出相当大的差异;并且站点可能在短时间内涌入大量请求,导致统计数据激增。
数据块相对来说比较大,单行数据存储内容相比监控类型多,如访问日志、安全日志等。
该类数据可容忍一定范围的误差,某些业务在做大量数据分析时,在一定范围的精度丢失并不影响实际结果。例如,我们用 IP 来作为独立访问的判断依据,那么我们就要把每个独立 IP 进行存储,在数据库中我们使用字符串方式存储 IP,那么一个 IPv4 最多需要 15 个字节。当有一个千万个独立 IP 时,则需要 15 byte * 10000000 ≈ 143 MiB,一个站点就需要消耗这么多资源,有上百上千的站点的情况下消耗就变得巨大,IPv6 消耗更甚,此时则可以牺牲精准度,选择更节省资源、更高效的统计方式实现。
监控型数据用于实时监控,要求精确且占用资源少;统计型数据需聚合多节点数据,适用于日志和安全分析,数据量大且容忍误差。两者在数据精度、实时性和资源需求上有明显区别,在落地时可针对不同数据类型做定向优化。
业务调整
站点流量统计添加「未缓存流量」,「命中流量」更名「缓存流量」。保留「回源流量」?
移除站点统计中「独立IP访问」概览和图表统计。
移除站点统计中「命中率」概览。
移除站点统计中「访问用户分布」和「状态码监控」。
移除节点带宽概览数据。
节点统计数据不做合计统计,每个节点数据单独展示。
快捷时间筛选调整为近6小时、近24小时、近7天、近30天?如果跨天有性能问题则保持现在逻辑只能允许一个自然日来查询。
数据采集频率、展示最小粒度均为一分钟。站点统计动态粒度?
增加数据保留最大天数,用户根据自己资源情况调整保存时间。最大90天?
全局安全配置「托管规则」更名为「内置规则」。ps:内置规则和自定义规则分割有利于以后更新内置规则策略。
技术调整
站点统计
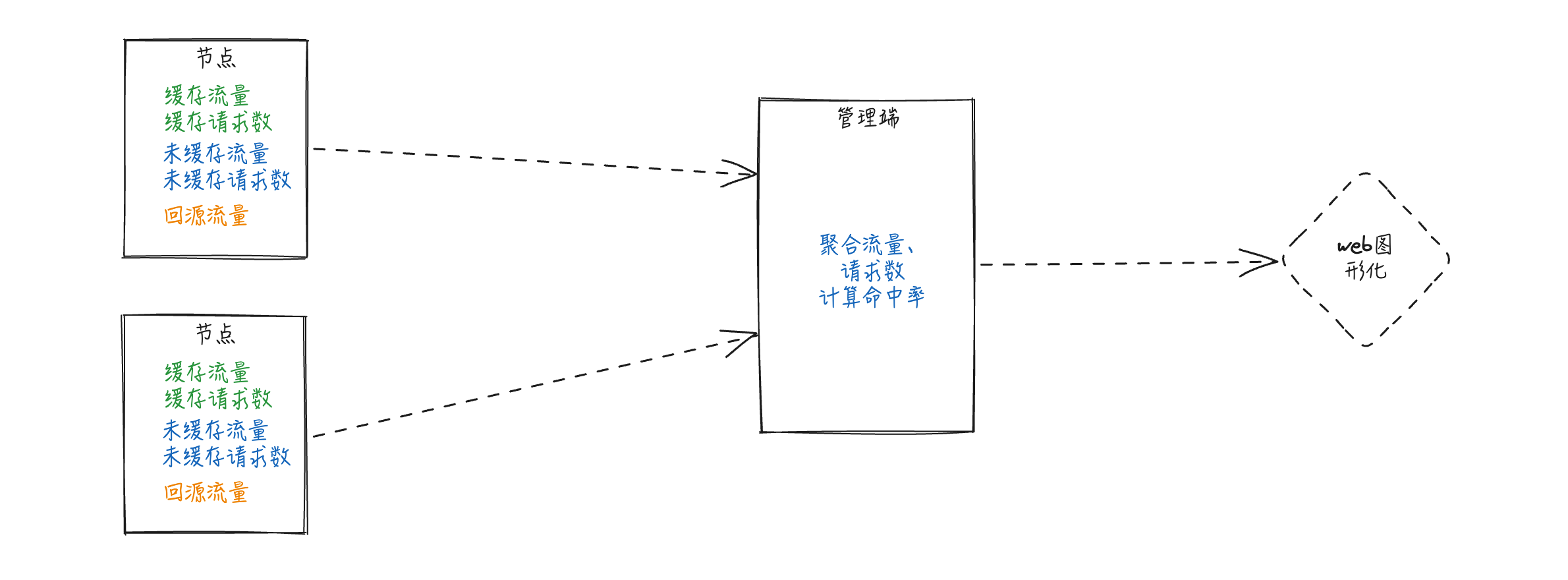
站点主要数据为:计费流量、缓存流量、未缓存流量、回源流量、请求数、命中率。
在当前版本计费流量是抓取节点网卡上行获取后由节点直接发送到管理端,其他的流量和请求数则是通过访问日志统计而来。
在新的版本中,流量统计则由节点分别统计好各站点的流量情况,定期发送到管理端,管理端聚合各个节点数据后图形化展出。
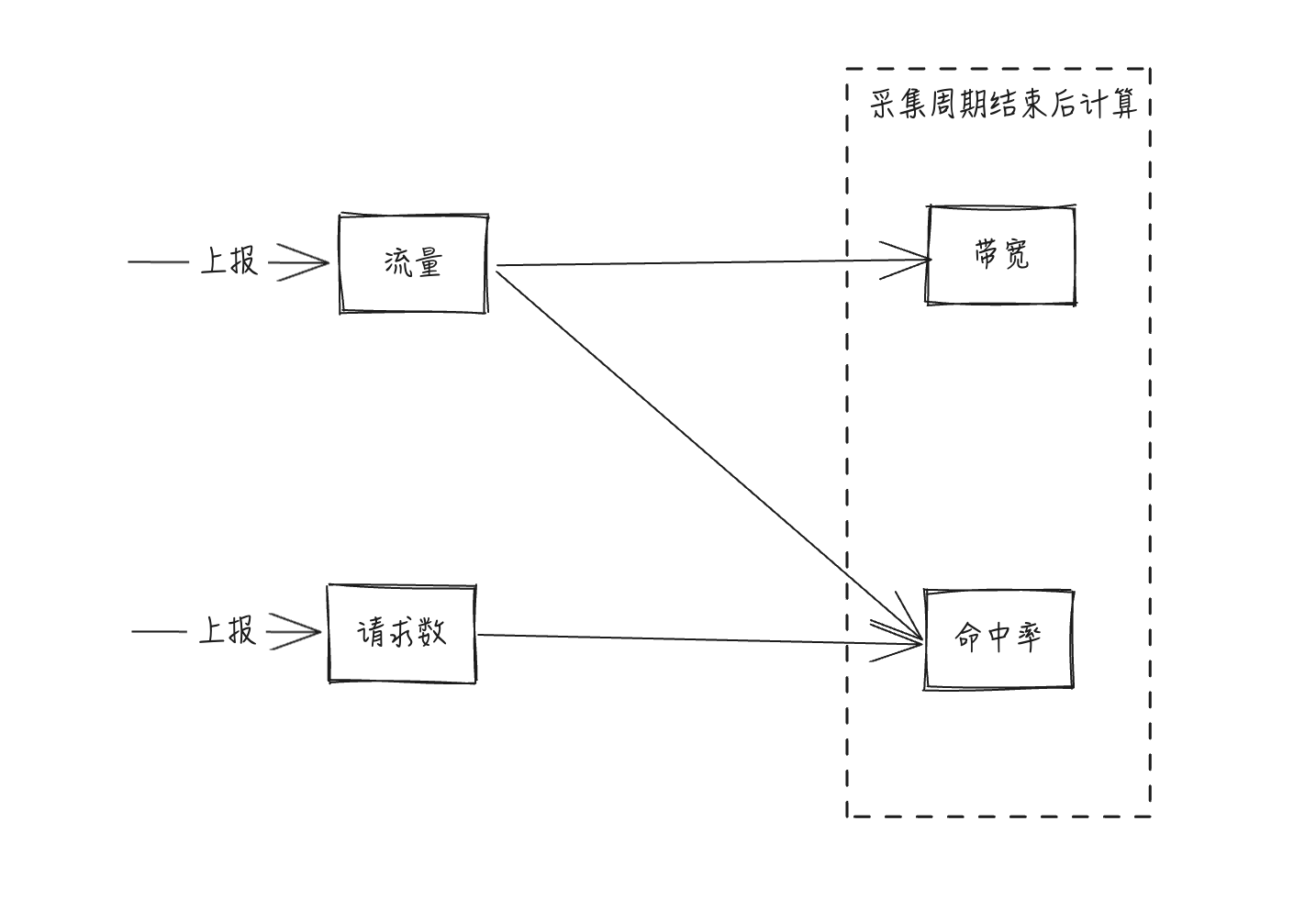
站点带宽计算规则:1分钟内流量总值 / 60秒 * 8 = 1分钟带宽值
节点上报数据不能保证数据同一时间到达管理端,所以带宽、命中率计算需要在本次采集周期结束后开始。
技术方案
指令位置
log_by_lua_file
缓存流量、未缓存流量获取方式
-- 表示发送给客户端的总字节数,包括响应头和响应体
local bytes_sent = ngx.var.bytes_sent
回源流量获取方式
-- 获取从上游服务器接收到的字节数
local upstream_bytes_received = ngx.var.upstream_bytes_received
缓存命中判断
命中后写入上下文中,例如:ngx.ctx.Cachehit = true
统计时根据判断字段命中
方案一
直接使用openresty中的共享内存,进行计数,通过http上报统计数据
优势
处理简单,所有进程之间都由一个共享内存进行统计,并上报
风险
共享内存在高并发下,可能存在锁的竞争问题
方案二
每个进程各自计数,各自上报
优势
处理简单,并且没有共享内存锁的竞争问题
风险
每个节点上报次数会根据进程数来上报,上报数会多一些,并发上报问题可在项目启动时使用一次性定时任务错开上报时间,例如:
联系邮箱:sales@99cdn.com
授权平台:www.99cdn.com
云平台:www.vmrack.com